
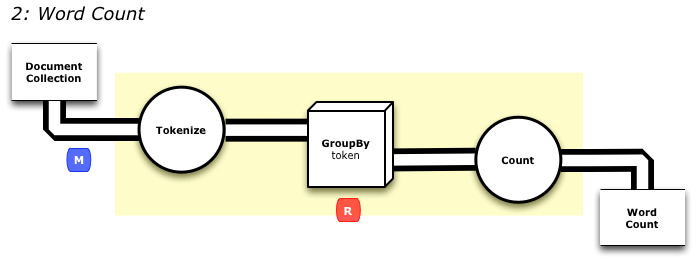
This Blog is intended to give a detailed explanation of an word count MapReduce program architecture, which will help the MapReduce starters and programmers to learn the need of Mapper class and its functions in the mapreduce programs.
Before moving further let us know about the most important daemons in hadoop mapreduce framework which should be known by every hadoop enthusiast. Below are the hadoop daemons and its characters / functions.
Namenode: A master daemon which stores the addresses of the data or the blocks of the input file which are present in the Data nodes.
Data node: Data nodes are the slave daemons of Namenode, which stores the actual data.
Resource Manager: It is the Master Daemon which allocates resources to its slave daemons ( Node Manager) to perform Mapreduce operations on the data which is present in the data nodes.
Node Manager: This is the daemon which is responsible for performing Mapreduce operations on the data which is present in the different data nodes on the permission of its master daemon Resource Manager.
We expect the readers to have basic knowledge on Big Data and MapReduce mapper class function, refer the below link to get the basics of Big data.
https://bigishere.wordpress.com/
So, from the above part we got to know the character or nature of the hadoop daemons. In the below steps we have explained that how these daemons helps to execute MapReduce program on the datasets which are present in the datanodes.
MapReduce Program Execution architecture
- Client submits Job to the Namenode
- Name node finds the block addresses where the actual data is stored in the different data nodes in the hadoop cluster.
- Resource manager submits jobs the to Node Manager
- Node Manager will perform the Mapreduce operation on the data which is present in the data nodes and the output result will be stored in the prescribed hdfs directory
Now let us go to the Program Part.
Minimum requirements
- Input text file
- Any Linux operating system with pre installed hadoop settings
- The mapper, reducer and driver classes to process the input files
How data is read from the data nodes
Hadoop was designed to work on key and value pairs only. i.e, the mapper and reducer function can only work on the input file key and value pairs. So, before reaching the mapper part the corresponding input split will be converted into the key value pairs according to the type of the input file. And these implementation is done by a predefined interface in hadoop framework known as Record Reader.
Record reader is an predefined interface which knows only to read one record (line) at a time from its corresponding input split and it converts the entire record (line) into key,value pairs depending on the file format.
In our case we have considered a text input format file where the input key will be byte offset of the beginning of the line from the beginning of the file and the value will be the entire record( row / line)
Once the Record reader converts a line into key value pairs these key value pairs will be sent to map method via mapper class to perform map code operation on the input splits.
Mapper Class
The map phase is the first primary phase of hadoop mapreduce programming structure which is responsible for performing operation on the provided input dataset.
The Mapper class is a generic type, with four formal parameter types that specify the input key, input value, output key and output value types of the map function. In our word count Mapper class example we choose a text format file with few lines of text, where the input key will be of long integer offset type, the input value is line of text type, the output key will be a word (Text), and the output value is an integer value 1 assigned to each word.
Expected output of Word Count Mapper class
The main goal of the word count mapper class is to form key value pairs for each word as <word,one> and push the result to the output context.
Example consider there are two lines of text in the provided input file:
input:
|
1
2
3
|
Hello Good Morning
Hello Good Evening
|
In map phase the sentence would be split as words and form the initial key value pair as shown below
output:
|
1
2
3
4
5
6
7
8
9
10
11
|
<Hello,1>
<Good,1>
<Morning,1>
<Hello,1>
<Good,1>
<Evening,1>
|
Mapper Class Code
PROBLEM STATEMENT
To form key value pairs for each word as <word,one> and push the result to the output context.
SOURCE CODE
|
1
2
3
4
5
6
7
8
9
10
11
12
|
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
|
The explanation for the code in each line of the above Mapper is:
- In line 1 we are taking a class by name WordCount
- In line 2 we are extending the Mapper default class having the arguments keyIn as LongWritable and ValueIn as Text and KeyOut as Text and ValueOut as IntWritable.
- In line 3 we are declaring a IntWritable variable ‘one’ with value as 1
- In line 4 we are declaring a Text variable ‘word’ to store the output keys
- In line 5 we are overriding the map method which will run one time for every line.
- In line 6 we are storing the line in a string tokenizer variable itr
- In line 7 we have given an while condition on the variable itr if it as one or more tokens then it will enter the while loop.
- In line 8 Assign each word from the tokenizer(of String type) to a Text word
- In line 9 Form key value pairs for each word as <word,one> and push it to the output context
Once the Mapper class output is stored in the output context buffer these output key value pairs will be passed to the shuffle and sort phase and are further sent to the reducer phase where the aggregation of the values is performed.
Thus, we hope this blog helped you to get a grip on MapReduce programming Mapper class function. You can refer the our next blog to know about the hadoop Sort and Shuffle process.
Keep visiting our website for more post on Big Data and other technologies.
https://bigishere.wordpress.com/
Regards
Anand Pandey
